

Wat als het geen bubbel is?
Iedereen vergelijkt AI met de dotcom-crash. Maar wat als je brein exponentiële groei gewoon niet aankan?


Op elk AI-event dat ik dit jaar bijwoon, hoor ik dezelfde vraag. Van directieleden, van managers, van consultants: “Luciano, wanneer barst de bubbel?” Ze zeggen het alsof het een vaststaand feit is. Alsof het alleen nog om timing gaat. En eerlijk, ik snap het. De vergelijking met de dotcom-crash voelt logisch. Absurde waarderingen, FOMO die door de markt giert, bedrijven die meer geld verbranden dan ze verdienen. Maar deze week draai ik het om. Want bijna niemand stelt de tegenvraag: wat als het niet zo is? En belangrijker nog: wat kost het ons om er steeds van uit te gaan dat het een bubbel is?
Waarom “bubbel” zo lekker klinkt
Het bubbel-argument is niet dom. Het is zelfs behoorlijk overtuigend. Dus laat me eerst eerlijk zijn over waarom het zo aannemelijk voelt.
Kijk naar de waarderingen. Anthropic, het bedrijf achter Claude, werd vorige week gewaardeerd op 380 miljard dollar. Hun verwachte omzet voor komend jaar: 14 miljard. Dat is 27 keer de omzet. Probeer dat maar eens te verdedigen met een traditioneel waarderingsmodel.
Kijk naar de RAM-markt. Samsung, SK Hynix en Micron verschuiven hun chipfabrieken richting premium AI-geheugen (HBM), waardoor gewone DRAM schaarser en duurder wordt. Analisten verwachten dat Samsung’s opbrengst per geheugenbit in 2026 met meer dan 100 procent stijgt. Dat voel je straks in de prijs van je volgende laptop, je telefoon, zelfs je televisie.
En dan de capex-cijfers. De vijf grootste techbedrijven geven in 2026 samen meer dan 600 miljard dollar uit aan AI-infrastructuur. Datacenters, chips, koeling, stroomnetwerken. Als de vraag tegenvalt, heb je lege hallen van hier tot Tokio.
Dus ja. Als iemand zegt “dit is een bubbel”, kan diegene dat onderbouwen. De patronen lijken op de dotcom-tijd. De getallen voelen absurd. En je brein zegt: dit kan niet standhouden.
Maar hier ga ik een andere kant op.
Je brein is gebouwd voor de savanne, niet voor exponentiële groei

Het probleem is niet dat de cijfers niet kloppen. Het probleem is dat je brein niet gebouwd is om ze te interpreteren.
Probeer dit. Stel je voor dat je één vel papier 42 keer dubbel vouwt. De meeste mensen schatten dat het resultaat een paar meter hoog is. De werkelijkheid: het reikt tot de maan. 384.400 kilometer. Van een vel papier. Dat is wat exponentiële groei doet met je intuïtie. Het voelt onschuldig, totdat het plotseling absurd wordt.

En precies dat patroon speelt zich nu af bij AI.
De rekenkracht die naar het trainen van AI-modellen gaat verdubbelt ruwweg elke vijf tot zes maanden. In twee jaar zijn dat vier tot vijf verdubbelingen. Dat is 16 tot 32 keer zoveel rekenkracht. En de prestaties schalen mee: niet lineair, maar voorspelbaar consistent. Meer compute levert meetbaar betere resultaten op. Dat zijn de zogenaamde scaling laws, bevestigd over meerdere ordes van grootte.
Concreet voorbeeld. SWE-bench is een benchmark die meet hoe goed AI echte softwareproblemen oplost. In 2023 scoorden de beste modellen 4,4 procent. Een jaar later: 71,7 procent. Van bijna niets naar bijna alles. In twaalf maanden. Dat is geen hype. Dat is een meetbaar resultaat op een gestandaardiseerde test.
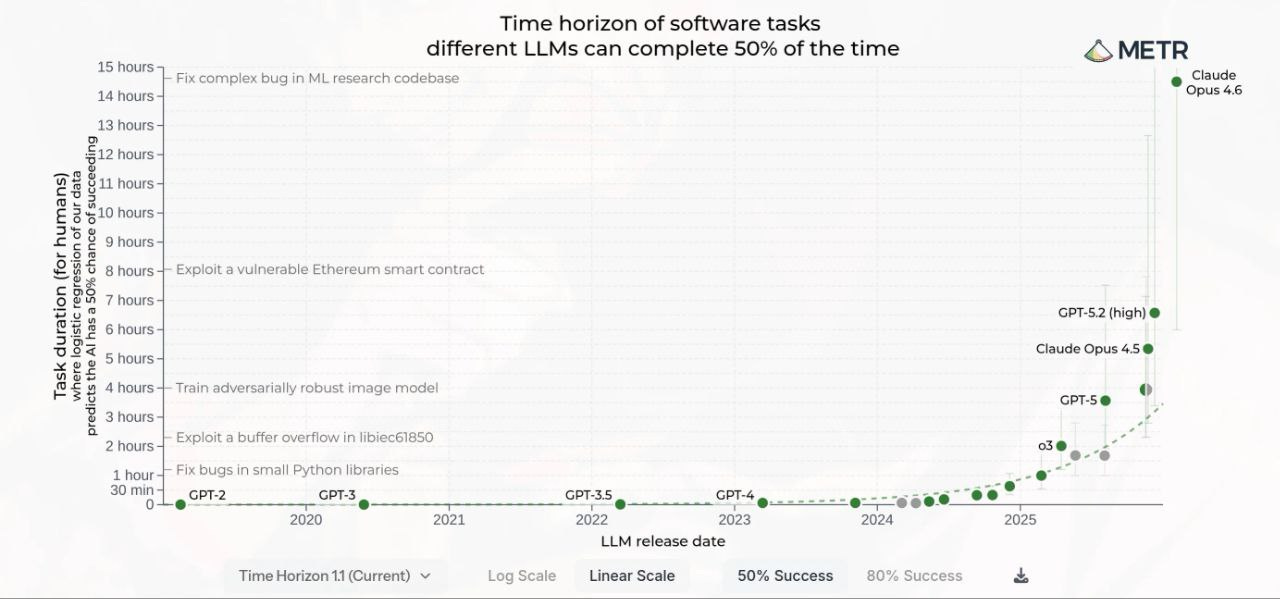
En het gaat niet om één curve. Er zijn er minstens zes die tegelijkertijd spelen. De rekenkracht groeit. De modellen worden per iteratie beter. Optimalisaties stapelen op. Het aantal gebruikers explodeert (en die leveren feedbackdata waarmee modellen weer verbeteren). Meer kapitaal stroomt naar de winnaars. En onderzoekers worden zelf productiever omdat ze AI gebruiken om AI te bouwen.
Zes tandwielen die elkaar aandrijven. Tegelijkertijd.
Dus als je brein zegt “dit kan niet kloppen, dit moet een bubbel zijn”, dan is er een alternatieve verklaring: je brein is simpelweg niet gebouwd om zes gelijktijdige exponentiële curves te verwerken. Net zoals je intuïtie faalt bij dat vel papier.
De dotcom-les die iedereen verkeerd leest
De dotcom-vergelijking is populair. Maar de meeste mensen trekken er de verkeerde conclusie uit.
Bij de dotcom-crash verloren investeerders triljoenen. Pets.com ging failliet. Webvan ging failliet. Het was echt pijnlijk. Maar de cruciale les is niet “internet was nep.” De les is: de waarderingen waren een bubbel, de technologie was dat niet.
De glasvezelkabels die in de hype-jaren werden gelegd? Die vormen nog steeds de ruggengraat van het internet. Amazon verloor 90 procent van zijn beurswaarde en werd vervolgens een van de waardevolste bedrijven ter wereld. Google werd opgericht in 1998, midden in de gekte.
En hier zit een belangrijk verschil met vandaag. Bij de dotcom investeerden mensen in websites en domeinnamen. Virtuele assets die van de ene op de andere dag waardeloos konden worden. Wat er nu gebouwd wordt, is fysiek. Datacenters. Stroomnetwerken. Chipfabrieken. Koelinstallaties.

McKinsey schat dat er richting 2030 wereldwijd 6,7 biljoen dollar nodig is aan datacenter-investeringen. En die investeringen leunen steeds minder op training (het eenmalig bouwen van modellen) en steeds meer op inference: het dagelijkse gebruik door miljoenen mensen en bedrijven.
Dus zelfs als waarderingen corrigeren (en dat kan), zelfs als de helft van de AI-startups failliet gaat (en dat gaat waarschijnlijk gebeuren): de infrastructuur blijft. De capaciteit blijft. De technologie gaat niet weg.
Dalende aandelenkoersen maken de technologie niet minder echt.
Wat het ons kost om steeds “bubbel” te roepen

En hier kom ik bij de vraag die mij het meest bezighoudt. Niet “is het een bubbel?” Maar: wat kost het ons om het steeds zo te noemen?
Want woorden sturen gedrag. Als het dominante verhaal “bubbel” is, gaan bedrijven wachten. “We zien het wel.” “Laten we eerst even afwachten.” Ik hoor het letterlijk in bestuurskamers.
Er is ook iets psychologisch aan de hand. “Bubbel” roepen is veilig. Als het klopt, was je de slimme die het zag aankomen. Als het niet klopt en je hebt gewacht, kun je altijd zeggen “ja, maar iedereen dacht dat.” Het is een strategie om jezelf in te dekken. Maar het is geen strategie om vooruit te komen.
Kijk naar de feiten. PwC ondervroeg dit jaar CEO’s wereldwijd. 56 procent zei geen meetbare omzetgroei of kostenbesparing te zien door AI. Klinkt als bewijs voor een bubbel, toch?
Maar kijk naar de andere kant. Veldonderzoek van MIT laat zien dat ontwikkelaars met AI-tools zo’n 26 procent productiever zijn. In klantenservice meet Oxford een productiviteitswinst van 15 procent. En 82 procent van professionals gebruikt generatieve AI inmiddels minstens wekelijks.
Het gat tussen die twee werelden vertelt het echte verhaal. De technologie werkt. Het probleem zit bij organisaties die nog niet weten hoe ze het moeten inbedden. Dat is geen bubbel. Dat is een implementatiefase. Precies zoals internet eind jaren negentig: iedereen had een website, bijna niemand had een businessmodel. Tot Amazon, Google en later Facebook het kraakten.
Dus wat laten we liggen door steeds “bubbel” te roepen? De kans dat we op het steile stuk van een S-curve zitten. De fase waarin vroege bewegers een voorsprong opbouwen die later bijna niet in te halen is.
Denk aan samengestelde rente. Elk kwartaal dat je investeert in AI-kennis, in processen, in experimenteren, bouwt voort op het vorige kwartaal. Elk kwartaal dat je wacht, loop je niet een beetje achter. Je loopt exponentieel achter. Want de kennis en ervaring die je concurrent opbouwt, versnelt alles wat daarna komt.
Dat hoeft niet te betekenen dat je morgen alles moet omgooien. Maar het betekent wel dat “wachten tot de bubbel barst” alleen werkt als het daadwerkelijk een bubbel is. En als het dat niet is, heb je jarenlang aan de zijlijn gestaan terwijl de rest in beweging was.
Of het nu een bubbel is of niet: de veiligste strategie is dezelfde. Begin klein. Experimenteer. Bouw kennis op. Want als het barst, heb je geleerd. En als het niet barst, heb je een voorsprong.
Dus: kun jij het je veroorloven om ervan uit te gaan dat het een bubbel is?
Ook het vermelden waard
Claude Sonnet 4.6 en Gemini 3.1 Pro: twee modelreleases in een week Anthropic lanceerde Sonnet 4.6, dat op veel benchmarks het oude Opus-topmodel evenaart voor een fractie van de kosten. In dezelfde week bracht Google Gemini 3.1 Pro uit, met een score van 77,1 procent op ARC-AGI-2 (meer dan het dubbele van de vorige versie). Twee grote spelers die tegelijkertijd forse sprongen maken. Dat past bij het beeld van deze editie: de curve verstomt niet, ze versteilt.
General Catalyst investeert $5 miljard in AI in India Het Silicon Valley-fonds General Catalyst kondigde aan de komende vijf jaar 5 miljard dollar te investeren in India, specifiek gericht op AI-deployment. Niet in het bouwen van frontier-modellen, maar in het uitrollen ervan op schaal: gezondheidszorg, fintech, defensie. India trekt inmiddels meer dan 200 miljard dollar aan AI-infrastructuurinvesteringen aan. Het kapitaal stroomt niet alleen harder, het stroomt breder. En dat is geen bubbel-patroon.
Andrej Karpathy bouwt in 1 uur een complete fitness-app met AI Karpathy (mede-oprichter OpenAI, voormalig hoofd AI bij Tesla) wilde zijn cardio beter tracken. Hij liet Claude de API van zijn loopband reverse-engineeren, de data verwerken en een compleet dashboard bouwen. Kosten: 1 uur. Twee jaar geleden: 10 uur. Zijn punt: de app store als concept is achterhaald. De toekomst is AI dat ter plekke software bouwt, precies op maat. Het was geen demo op een podium. Het was een donderdagochtend.
ElevenLabs lanceert eerste verzekeringspolis voor AI-stemagents ElevenLabs introduceerde samen met verzekeraar AIUC de eerste polis die AI-stemassistenten verzekert alsof het medewerkers zijn. Voorwaarde: systemen moeten meer dan 5.000 vijandige simulaties doorstaan op veiligheid, hallucinaties en prompt injection. Dit lost een van de grootste drempels op voor AI in bedrijfskritische omgevingen: aansprakelijkheid. Als je agent verkeerde informatie geeft of data lekt, dekt de verzekering het. De overgang van “leuk experiment” naar “productie” wordt hiermee concreter.