

Playbook: LLM Wiki. Alles wat je leest onthouden. Letterlijk.
Je leest honderden artikelen per jaar. Hoeveel kun je er nog terughalen?


Je leest elke week tien, vijftien artikelen over AI. Podcasts, nieuwsbrieven, research papers, X-threads. Je kopieert de interessante stukken naar Notion, bookmark de rest, en stuurt af en toe iets door naar een collega. Na drie maanden heb je honderden bronnen verzameld. En je vindt niks meer terug.
Je weet dat je ergens iets hebt gelezen over de impact van AI op middenmanagement. Maar waar? Was het die podcast van twee weken geleden? Dat artikel op Ars Technica? Die tweet die je had opgeslagen? Je gaat zoeken in je notities, scrolt door je bookmarks, doorzoekt je e-mail. Na twintig minuten geef je het op en google je het opnieuw.
Herken je dat? Dan is dit playbook voor jou.
Andrej Karpathy, medeoprichter van OpenAI en voormalig AI-directeur bij Tesla, publiceerde vorige week een idee dat in twee dagen meer dan 5 miljoen views haalde. Niet een paper, niet een product, maar een workflow: gebruik een LLM om een persoonlijke wiki voor je bij te houden. Geen chatbot die je vragen beantwoordt en het dan weer vergeet. Een systeem dat elke bron die je erin stopt leest, samenvat, kruisverwijzingen maakt, en integreert in een groeiende kennisbank. Kennis die compound, net als rente op een spaarrekening.
Het mooiste: je hebt er geen database voor nodig. Geen vector embeddings, geen server, geen technische achtergrond. Het zijn gewoon markdown-bestanden in een map op je computer.
Wat is een LLM Wiki?
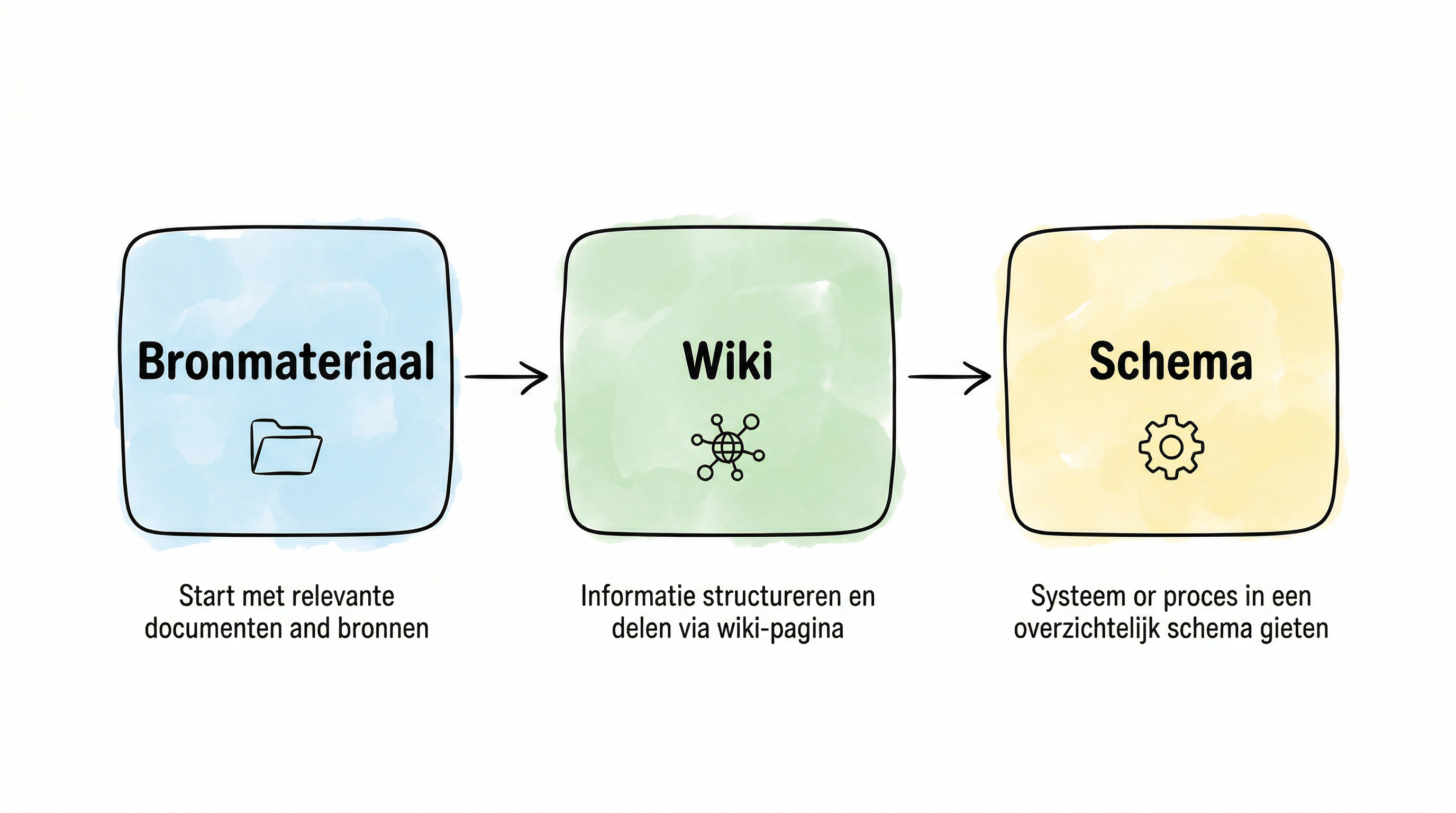
Het concept is verrassend simpel. Je hebt drie lagen.
Bronmateriaal. Een map met alles wat je verzamelt. Artikelen, PDF’s, notities, transcripten. Dit is je bibliotheek. De LLM leest hieruit maar verandert er niks aan.
De wiki. Een map met bestanden die de LLM voor je schrijft en bijhoudt. Samenvattingen, overzichtspagina’s, vergelijkingen, conceptuitleg. Alles in markdown, alles gelinkt. Dit is je kennisbank, en de LLM doet al het onderhoud.
Het schema. Een configuratiebestand (CLAUDE.md) dat de LLM vertelt hoe de wiki is opgebouwd, welke conventies er gelden, en wat er moet gebeuren bij het verwerken van nieuwe bronnen. Dit is de handleiding voor je assistent.
Vergelijk het met een kantoor. Het bronmateriaal is de stapel post die elke dag binnenkomt. De wiki is het archief dat je secretaresse bijhoudt: netjes gelabeld, kruisverwijzingen, alles vindbaar. Het schema is de instructie die je die secretaresse hebt gegeven: “Sorteer op onderwerp, maak bij elke nieuwe klant een apart dossier, en leg bij elke factuur een notitie over de betaalstatus.”
Alleen is deze secretaresse een LLM. En die wordt nooit moe van archiveren.
Hoe verschilt dit van wat je al kent?
Dit klinkt misschien als iets dat al bestaat. NotebookLM, ChatGPT met bestanden, Copilot in je apps. Maar er zit een fundamenteel verschil.
Al die tools werken met RAG: Retrieval Augmented Generation. Je uploadt bestanden, de AI doorzoekt ze bij elke vraag, en genereert een antwoord op basis van relevante fragmenten. Dat werkt prima voor simpele vragen. Maar de AI begint elke keer van nul. Er wordt niks opgebouwd. Stel een subtiele vraag die informatie uit vijf documenten vereist, en de AI moet elke keer opnieuw zoeken, samenvoegen, en beredeneren. Niks wordt onthouden. Niks wordt rijker.
Een LLM Wiki werkt anders. Als je een nieuw artikel toevoegt, leest de LLM het niet alleen. Hij verwerkt het. Hij schrijft een samenvatting, update bestaande pagina’s, voegt kruisverwijzingen toe, noteert waar nieuwe informatie oude claims tegenspreekt, en versterkt of nuanceert de bestaande synthese. De kennis wordt één keer gecompileerd en daarna bijgehouden. Niet elke keer opnieuw afgeleid.
Dat is het kernverschil: de wiki is een persistent, groeiend artefact. De kruisverwijzingen zijn er al. De tegenstrijdigheden zijn al gesignaleerd. De synthese bevat alles wat je ooit hebt gelezen. Met elke bron die je toevoegt en elke vraag die je stelt, wordt de wiki rijker.
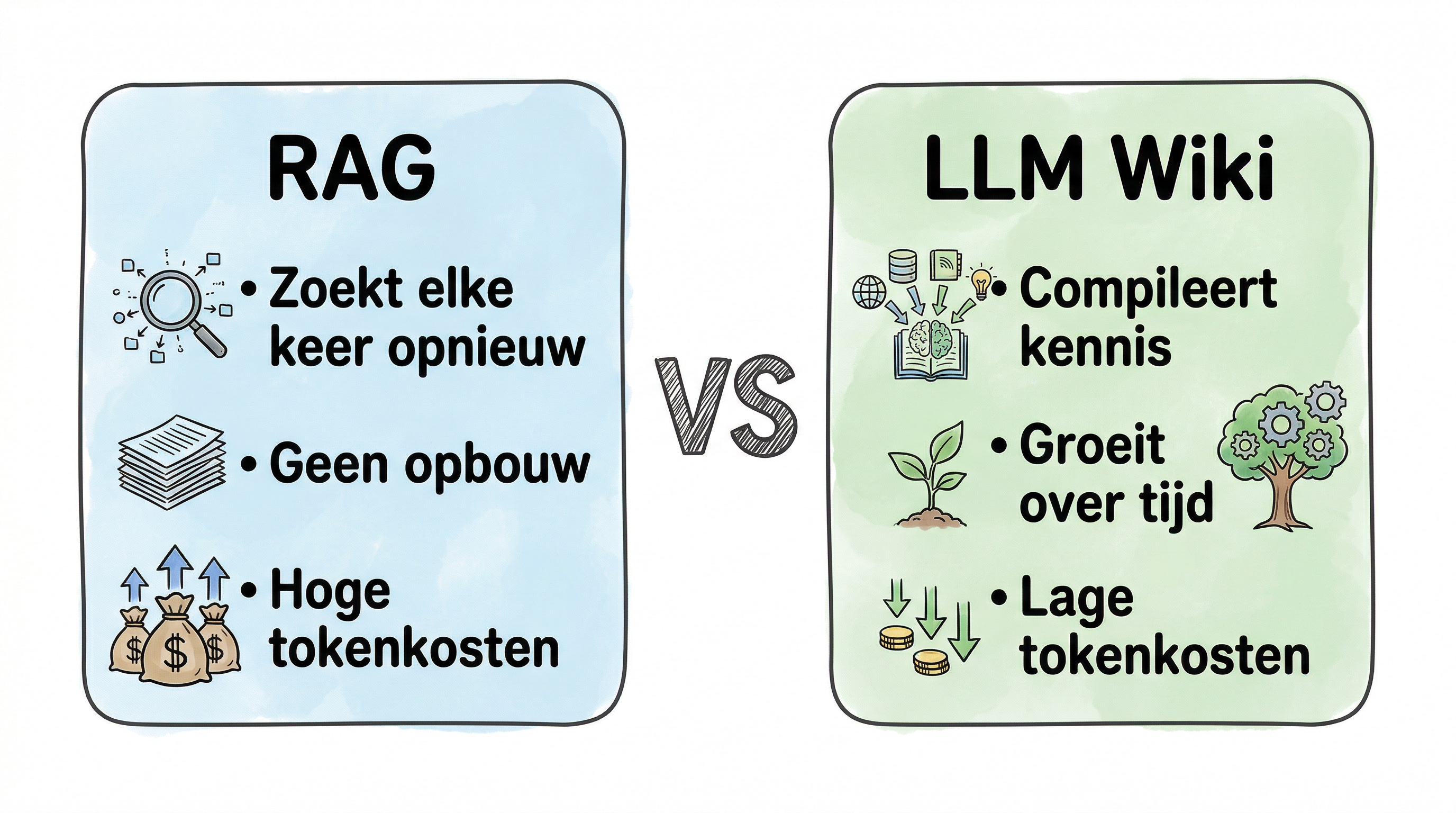
NotebookLM / ChatGPT:
Zoekt in ruwe bestanden bij elke vraag
Kennis wordt elke keer opnieuw afgeleid
Na 100 bronnen: langzamer, fragmentarischer
Onderhoud: nul (maar ook nul opbouw)
Kosten per vraag: hoog (hele documenten doorzoeken)
Wat je overhoudt: chatgeschiedenis die je weggooit
LLM Wiki:
Bouwt gestructureerde wiki op die groeit
Kennis wordt gecompileerd en bijgehouden
Na 100 bronnen: rijker, meer verbanden
Onderhoud: de LLM doet het
Kosten per vraag: laag (compacte wiki raadplegen)
Wat je overhoudt: een doorzoekbare kennisbank
Een concreet voorbeeld. Iemand had 383 losse bestanden en meer dan 100 meeting-transcripten. Na het omzetten naar een LLM Wiki daalde het tokengebruik per vraag met 95%. Niet omdat de kennis verdween, maar omdat die was gecompileerd in compacte, gestructureerde pagina’s in plaats van elke keer honderden losse documenten te doorzoeken.
Het slimme mechanisme: compileren vs zoeken
Waarom werkt dit zo goed? Omdat het aansluit bij hoe kennis eigenlijk werkt.
Vergelijk het met studeren voor een tentamen. Je kunt elke keer je boek openslaan en de relevante passages zoeken. Dat is RAG. Of je kunt samenvattingen maken, mindmaps tekenen, en aantekeningen schrijven in je eigen woorden. Dat is de wiki-aanpak. Na een maand studeren heb je bij de eerste methode nog steeds alleen een boek. Bij de tweede heb je een persoonlijk naslagwerk dat precies aansluit bij jouw begrip.
De LLM doet dat samenvattingswerk voor je. Elke keer als je een nieuw artikel toevoegt, doorloopt hij drie stappen:
Wat is hier nieuw? (samenvatten en opslaan)
Wat raakt dit dat we al weten? (kruisverwijzingen updaten)
Spreekt dit iets tegen dat we eerder hebben opgeschreven? (tegenstrijdigheden signaleren)
Die drie stappen, herhaald over tientallen bronnen, bouwen een kennisbank op die steeds rijker en nauwkeuriger wordt. En de LLM houdt ook een index bij (een soort inhoudsopgave), waardoor hij bij volgende vragen niet alle pagina’s hoeft te lezen maar direct naar de relevante informatie kan navigeren.
Waarom zou je dit willen?
Vier redenen.
1. Je kennis verdampt niet meer. Hoeveel artikelen heb je het afgelopen jaar gelezen? Honderden waarschijnlijk. Hoeveel kun je nog terughalen? Een handvol. Met een LLM Wiki wordt elke bron die je leest permanent onderdeel van een doorzoekbare, gestructureerde kennisbank. Niet als een bookmark die je vergeet, maar als geïntegreerde kennis met kruisverwijzingen.
2. Je ziet verbanden die je zelf mist. Na dertig artikelen over AI-implementatie begint de wiki patronen te tonen. Misschien blijkt dat vier onafhankelijke bronnen hetzelfde probleem beschrijven vanuit verschillende invalshoeken. Of dat een claim in artikel 7 wordt tegengesproken door data in artikel 23. Die verbanden leg je handmatig nooit. De LLM doet het automatisch.
3. Het is een voorsprong die niet in te halen is. Dit is misschien wel het belangrijkste punt. De waarde van zo’n wiki zit niet in de setup. Die is in vijf minuten klaar. De waarde zit in de context die erin groeit. Elke bron die je verwerkt, elke vraag die je stelt, elke correctie die je doorvoert, het wordt allemaal onderdeel van een steeds rijker systeem. Na zes maanden heb je een kennisbank die precies aansluit bij jouw werk, jouw vragen, en jouw domein. Als iemand dan pas begint, zijn ze niet alleen laat met de tool. Ze missen zes maanden aan opgebouwde intelligentie. Dat is hetzelfde als compound interest op een spaarrekening: het verschil zit niet in de storting, maar in de tijd.
4. Het kost je bijna niks. Geen subscription, geen database, geen server. Obsidian is gratis. Claude Code kost je tokens, maar minder dan je denkt, want de wiki is compact. Vergelijk dat met een Notion-abonnement, een NotebookLM-limiet, of een enterprise RAG-pipeline. Dit is een map met tekstbestanden op je eigen computer. Niks meer, niks minder.
Concrete voorbeelden
Consultant: Je leest rapporten, brancheanalyses, en klantdocumenten voor acht verschillende opdrachtgevers. Je wiki houdt per klant bij wat je hebt gelezen, welke trends relevant zijn, en waar overlap zit tussen projecten. Als een klant vraagt “wat doen vergelijkbare organisaties?”, heb je het antwoord in seconden.
Marketeer: Je volgt tien concurrenten, leest hun blogs, analyseert hun campagnes, en houdt productlanceringen bij. Je wiki bouwt een competitieve analyse op die elke week automatisch rijker wordt. Geen handmatig spreadsheet meer bijhouden.
Onderzoeker: Je leest papers, volgt conferenties, en verzamelt data. Je wiki bouwt een literatuuroverzicht op dat zichzelf bijhoudt. Nieuwe papers worden automatisch vergeleken met bestaande kennis en ingedeeld bij de juiste thema’s.
Manager: Je hebt meetings, leest rapporten, en ontvangt statusupdates. Je wiki wordt je organisatorische geheugen. “Wat hebben we drie maanden geleden besloten over project X?” is een vraag die je wiki in seconden beantwoordt.
Ondernemer: Je volgt markttrends, leest over nieuwe technologieën, en evalueert kansen. Je wiki wordt je strategische radar. Na een half jaar heb je een persoonlijk overzicht dat geen analist je kan geven, want het is gefilterd door jouw perspectief en jouw vragen.
Contentmaker: Je produceert wekelijks content en leest daarvoor tientallen bronnen. Je wiki houdt bij over welke onderwerpen je al veel hebt geschreven, waar gaten zitten, en welke bronnen je nog niet hebt benut. In plaats van elke week opnieuw te bedenken “waar heb ik het al over gehad?”, vraag je het aan je wiki. Die weet het. Ik gebruik dit zelf voor mijn eigen contentproductie, en het verschil is enorm. Je ziet in één oogopslag waar kansen liggen die je anders had gemist.
Je eerste wiki in 5 minuten

Genoeg theorie. We gaan het opzetten. Je hebt twee dingen nodig: Obsidian (gratis) en Claude Code.
Stap 1: Installeer Obsidian
Download Obsidian via obsidian.md. Maak een nieuwe vault aan op een logische plek, bijvoorbeeld C:\Documenten\mijn-wiki of ~/Documents/mijn-wiki. Een vault in Obsidian is gewoon een map. Alles erin is puur tekst. Geen vendor lock-in, geen cloud-afhankelijkheid.
Stap 2: Maak de basisstructuur
Open je vault en maak twee mappen aan: raw en wiki. Meer heb je niet nodig om te beginnen.
mijn-wiki/
├── raw/ # Hier gooi je je bronnen in
├── wiki/ # Hier bouwt de LLM je kennisbank
└── CLAUDE.md # Instructies voor de LLMStap 3: Installeer Claude Code
Open een terminal en installeer Claude Code:
npm install -g @anthropic-ai/claude-codeNavigeer naar je vault-map en start Claude Code:
cd ~/Documents/mijn-wiki
claudeStap 4: Geef Claude het idee
Dit is de mooiste stap. Karpathy heeft zijn LLM Wiki-idee bewust abstract gehouden als een “idea file” dat je letterlijk kunt kopiëren en plakken in je LLM-agent. Dus dat is precies wat je doet. Kopieer de volledige tekst van Karpathy’s gist (je vindt het op GitHub, zoek op “karpathy llm-wiki”) en plak het in Claude Code. Dan voeg je er dit aan toe:
Je bent nu mijn LLM wiki agent.
Implementeer dit exacte idee-bestand als mijn volledige tweede brein.
Begeleid me stap voor stap. Maak het CLAUDE.md schemabestand aan met
volledige regels. Zet index.md en log.md op. Definieer map-conventies
en laat me de eerste ingest-voorbeelden zien. Vanaf nu volgt elke
interactie dit schema.Claude leest het idee, begrijpt het patroon, en bouwt de hele structuur voor je uit: een CLAUDE.md met alle regels, een index, een log, de juiste mappenindeling. Je hoeft niks zelf te configureren. Het idee-bestand is de instructie, Claude is de uitvoerder.
En dat is eigenlijk de kern van deze hele aanpak. Je geeft Claude niet een stappenplan, je geeft hem een concept. En hij bouwt de implementatie die past bij jouw situatie. Wil je een research-wiki? Dan maakt hij andere paginatypen dan wanneer je een persoonlijke wiki wilt. Wil je het in het Nederlands? Zeg het erbij. Claude past het schema aan.
Stap 5: Voeg je eerste bron toe
Drop een artikel in de raw/ map. Je kunt de Obsidian Web Clipper browser-extensie installeren om artikelen direct vanuit je browser naar je vault te sturen. Zeg dan tegen Claude: “Er staat een nieuw artikel in raw/. Lees het en bespreek de kernpunten met me.”
Claude leest het artikel, bespreekt de inhoud met je, en na jouw input integreert hij alles in de wiki. Bronpagina, conceptpagina’s, kruisverwijzingen, index-update. In één keer.
Open Obsidian naast je terminal. Je ziet de pagina’s verschijnen. Klik op de graph view en je ziet de eerste verbanden ontstaan. Dat is het. Vijf stappen, vijf minuten.
De drie niveaus
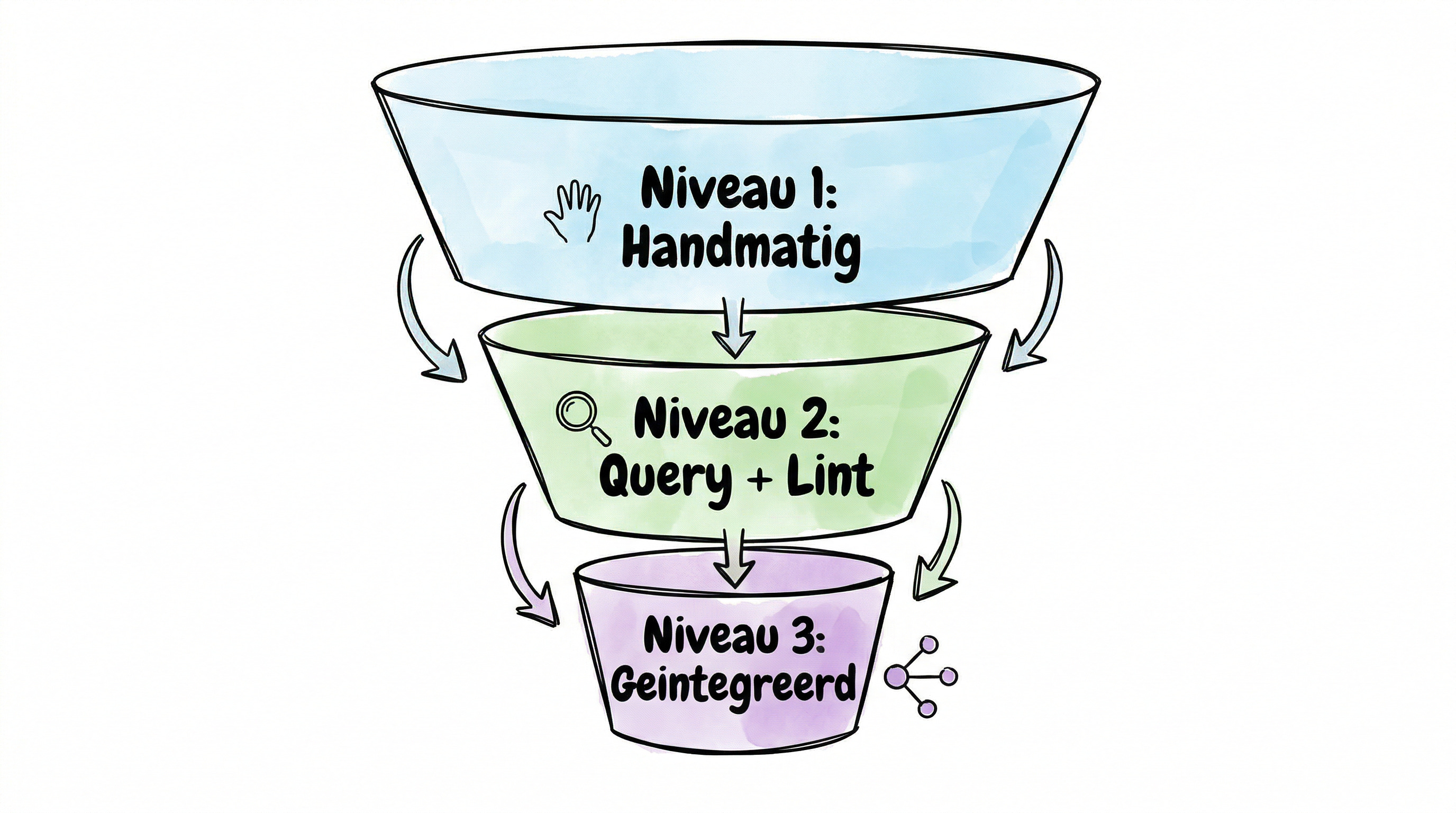
Net als bij onze eerdere playbooks zijn er niveaus van complexiteit. Begin bij niveau 1. Bouw van daaruit.
Niveau 1: Handmatige ingestie
Je voegt bronnen toe aan raw/, vertelt Claude dat er iets nieuws staat, en Claude verwerkt het. Je bent erbij, leest de samenvattingen, stuurt bij waar nodig. Dit is de basis en voor de meeste mensen meer dan genoeg.
Vergelijk het met een archivaris die je af en toe een nieuw document geeft. “Hier, verwerk dit.” De archivaris leest het, archiveert het, en je kunt later vragen stellen.
Niveau 2: Gestructureerd met query en lint
Je stelt actief vragen aan je wiki en laat goede antwoorden opslaan als nieuwe pagina’s. Je draait periodiek een lint-check: de LLM controleert de wiki op tegenstrijdigheden, verouderde informatie, en ontbrekende verbanden. Je wiki wordt niet alleen groter, maar ook gezonder.
Niveau 3: Geïntegreerd in je workflow
Je koppelt je wiki aan andere projecten. Je executive assistant leest je wiki als context. Je research-agent slaat bevindingen op in je wiki. Je wiki wordt het centrale geheugen van al je AI-tools. Niet één slimme tool, maar een kennislaag die al je tools slimmer maakt.
Denk er zo over na: AI-modellen worden beter, MCP-koppelingen worden beter, automatisering wordt makkelijker. Maar al die verbeteringen missen één ding: context over jou, jouw werk, en jouw domein. Die context is de ontbrekende laag. En dat is precies wat je wiki levert. Elke AI-tool die je vandaag gebruikt wordt direct beter als hij kan lezen wat jij de afgelopen maanden hebt verzameld, geanalyseerd, en opgebouwd.
Iemand die dit doet met zijn YouTube-kanaal liet 36 videotranscripten verwerken tot een doorzoekbare kennisbank. Nu kan zijn executive assistant automatisch context ophalen uit zijn “second brain” zonder elke keer tientallen bestanden te doorlezen. De hot cache (een compact bestand met de meest recente context) zorgt dat de meest relevante informatie altijd direct beschikbaar is.
Goed, dat was de basis. Wat hieronder staat is wat het verschil maakt tussen een wiki die na een week stoft en een wiki die je dagelijks gebruikt: het complete CLAUDE.md-template dat je kunt kopiëren en aanpassen, zes geavanceerde patronen (waaronder de hot cache en geautomatiseerd onderhoud), een werkend voorbeeld van een complete AI-research wiki, de zeven fouten die ik iedereen zie maken, en de eerlijke beperkingen die je moet kennen.
Nog geen abonnee? Je eerste playbook is gratis. Of deel The Human Loop met een collega en krijg gratis maanden cadeau.
Ik begin met het template dat ik zelf als startpunt gebruik.
