

Playbook: Context Engineering
De vaardigheid die het verschil maakt tussen een AI-stagiair en een AI-medewerker

Het onzichtbare plafond van Prompt Engineering

De kans is groot dat je de afgelopen maanden hebt geëxperimenteerd met AI. Je hebt ChatGPT gebruikt, misschien zelfs een Custom GPT gebouwd met je eigen documenten. Je hebt geprobeerd een proces te automatiseren. En de kans is even groot dat je tegen een muur bent gelopen.
De AI ‘begrijpt’ de unieke context van jouw bedrijf niet. Hij maakt dezelfde fouten opnieuw en opnieuw. Het voelt als een briljante stagiair die je elke ochtend opnieuw moet inwerken. Voor een simpele, losstaande taak werkt het prima. Maar voor de complexe, contextrijke processen die de kern van je bedrijf vormen? Daar faalt het.
Dit is de beperking van simpel ‘prompten’. We hebben geleerd hoe we een gesprek moeten voeren met AI, maar we hebben nog niet geleerd hoe we een betrouwbaar, autonoom systeem moeten bouwen met AI.
Dit is waar Context Engineering om de hoek komt kijken. Het is de overkoepelende discipline voor het bouwen van elk intelligent AI-systeem, van een robuuste Custom GPT tot een volledig autonome agent. Het is de cruciale, volgende stap die het verschil maakt tussen een AI die je helpt en een AI die voor je werkt. Dit playbook is jouw gids voor die transformatie. We gaan verder dan prompt-trucjes en geven je de architectuur voor het bouwen van robuuste, intelligente AI-systemen.
1: Van Prompten naar Architectuur

Om de kracht van Context Engineering te begrijpen, moeten we eerst het fundamentele verschil met Prompt Engineering helder hebben.
Prompt Engineering is een gesprek. Het is de kunst van het stellen van de juiste vraag om een goed antwoord te krijgen in een directe interactie. Jij bent de bestuurder die continu aan het stuur draait.
Context Engineering is architectuur. Het is de kunst van het ontwerpen van een systeem dat een AI-model programmatisch en dynamisch voorziet van de juiste informatie, op het juiste moment, om een complexe taak autonoom uit te voeren. Jij bent de architect die de blauwdruk van de snelweg ontwerpt, zodat de auto zelfstandig kan rijden.
De Beste Analogie: De Computer
Denk aan een Large Language Model (LLM) als de processor (CPU) van een computer. Het context window – de input die je het model geeft – is het werkgeheugen (RAM).
Prompt Engineering is wat je op een specifiek moment tegen de processor zegt.
Context Engineering is het vakkundig beheren van dat volledige werkgeheugen. Wat laad je in? Wat haal je eruit? Hoe zorg je ervoor dat alleen de meest relevante informatie beschikbaar is, zodat de processor zijn werk optimaal kan doen?
Waarom is dit de sleutel? Omdat de kwaliteit van de output van een LLM recht evenredig is met de kwaliteit van de input. Een ‘vervuild’ werkgeheugen met irrelevante, onjuiste of ontbrekende informatie leidt onvermijdelijk tot een slecht resultaat.
2: De Hoge Kosten van Slechte Context (De ‘Rework’ Epidemie)

Slechte context is niet alleen inefficiënt; het is actief schadelijk voor je productiviteit en innovatiekracht. Recent onderzoek van Stanford onder 100.000 ontwikkelaars toont een alarmerende trend: naïef gebruik van AI-coding-assistenten leidt tot een enorme hoeveelheid rework. Zelfs als er in eerste instantie tijd wordt gewonnen, wordt tot de helft daarvan weer weggegooid omdat de output slordig, incorrect of onvolledig is.
Voor complexe taken of het werken in bestaande, complexe systemen (’brownfield’ projecten) kan het zelfs contraproductief zijn. De AI vertraagt je meer dan hij versnelt. Dit is de pijn die elke professional herkent die verder is gegaan dan een simpel prototype.
De kosten van slechte context manifesteren zich op drie niveaus:
Verspilde Tokens (en Geld): Elke keer dat een AI-model onnodige informatie moet doorzoeken of de verkeerde tools gebruikt, verbrand je tokens. Dit is als water in een lekkende emmer gieten.
Slechte Beslissingen (en Resultaten): Een AI-agent die handelt op basis van onvolledige of verouderde context zal onvermijdelijk de verkeerde beslissingen nemen. Dit leidt tot fouten, frustratie en een gebrek aan vertrouwen in de technologie.
Stilgevallen Projecten: De meeste AI-projecten die in de pilotfase stranden, doen dat niet vanwege een slecht model, maar vanwege een falende contextstrategie. Het systeem kan simpelweg niet betrouwbaar functioneren in de complexiteit van de echte wereld.
3: De Vier Pijlers van Effectieve Context
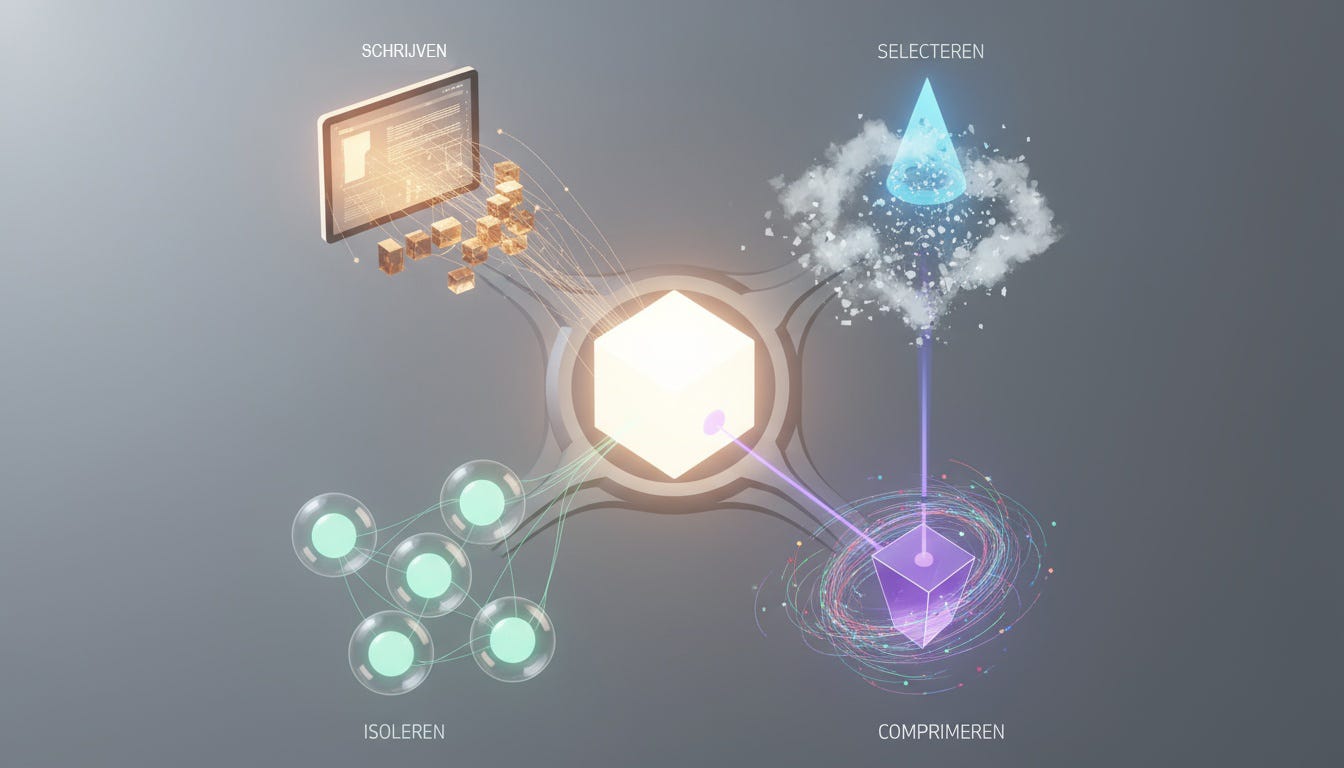
Hoe beheren we dat ‘werkgeheugen’ dan op een professionele manier? Context Engineering rust op vier fundamentele strategieën. Dit zijn de hoofdcategorieën in de ‘instructiehandleiding’ die je voor je AI-agent bouwt.
1. Schrijven: Het Geheugen van je Agent
Een agent die niets kan onthouden, is nutteloos. Deze strategie gaat over het geven van een ‘kladblok’ (scratchpad) en een langetermijngeheugen aan je AI. De agent schrijft belangrijke bevindingen, plannen en tussentijdse resultaten weg, zodat hij deze later kan raadplegen en niet telkens opnieuw het wiel hoeft uit te vinden.
2. Selecteren: De Juiste Kennis op het Juiste Moment
Je wilt niet je hele bedrijfsdatabase in het werkgeheugen proppen. Dat is inefficiënt en onbetaalbaar. Deze strategie gaat over het slim ophalen (retrieval) van alleen de meest relevante informatie. Denk aan:
Retrieval-Augmented Generation (RAG): Alleen de relevante paragrafen uit je kennisbank ophalen.
Tool Selectie: Alleen de beschrijvingen van de 3 meest relevante tools aanbieden uit een bibliotheek van 100.
Semantische Zoekopdrachten: De AI helpen om bestanden te vinden op basis van betekenis, niet alleen op basis van trefwoorden.
3. Comprimeren: Ruis Verwijderen, Signaal Versterken
Naarmate een taak vordert, raakt het werkgeheugen vol met gespreksgeschiedenis en tool-outputs. Deze strategie gaat over het periodiek ‘opruimen’ en samenvatten van de context, zodat alleen de essentie overblijft. Dit houdt de agent gefocust en het token-verbruik onder controle.
4. Isoleren: Complexe Taken Opbreken
Voor een zeer complexe taak wil je niet één agent met een overvol werkgeheugen. Deze strategie gaat over het inzetten van een team van gespecialiseerde ‘sub-agents’. Elke sub-agent krijgt zijn eigen, geïsoleerde context om een deeltaak op te lossen. Een ‘research-agent’ zoekt de informatie, een ‘analyse-agent’ verwerkt het, en een ‘schrijf-agent’ stelt het rapport op. Dit is de basis van schaalbare, multi-agent systemen.
Klaar om de Architect te Worden?

Je weet nu wat Context Engineering is en waarom het de onmisbare vaardigheid is om verder te komen dan het AI-plafond. Je begrijpt de vier strategische pijlers die de basis vormen voor het bouwen van robuuste, lerende AI-systemen.
Maar de echte waarde zit in de executie.
Hoe ontwerp je een effectieve ‘scratchpad’ voor je agent?
Welke RAG-strategie werkt het beste voor jouw use case?
Wat zijn de best practices voor het aansturen van multi-agent systemen zonder in chaos te verzanden?
En hoe bouw je een complete ontwikkelworkflow rondom deze principes?
Upgrade nu en krijg direct toegang tot De Diepte in: De Tactische Blauwdruk voor Context Engineering. Dit is geen theorie meer, dit is de handleiding die de pro’s gebruiken.
In het betaalde deel krijg je:
✅ Het Context-First Workflow Framework: Een stapsgewijs proces (Research, Plan, Implement) om elke complexe AI-taak te structureren.
✅ De ‘Intentional Compaction’ Techniek: Een praktische handleiding om je context te comprimeren en je token-verbruik met meer dan 40% te reduceren.
✅ Blauwdruk voor Multi-Agent Systemen: Hoe je sub-agents effectief inzet voor context-isolatie en complexe probleemoplossing, inclusief prompt-templates.
✅ De RAG-Toolkit voor de Praktijk: Concrete strategieën om je AI te verbinden met je bedrijfsdata, van semantisch zoeken tot het ranken van bronnen.
✅ Het ‘Spec-First’ Ontwikkelproces: Hoe je specificaties (de ‘menselijke’ context) de kern van je AI-ontwikkeling maakt om rework drastisch te verminderen.
