

Het einde van ‘Brute Force’ AI? | Twee 22-jarigen verslaan OpenAI | Waarom ‘Scaling’ faalt
Waarom AI-scaling faalt: MIT over de impact van AI op banen, en hoe twee jonge ondernemers OpenAI verslaan met een slimmere aanpak.

De afgelopen jaren gold in AI één simpele wet: groter is beter. Meer data, meer rekenkracht, meer geld. Twee 22-jarige studenten uit Beijing hebben deze week bewezen dat die wet is achterhaald. Met een fractie van de middelen versloegen ze de reuzen van OpenAI en Google, niet door harder te duwen, maar door slimmer te denken…
In deze editie:
Waarom efficiënte architectuur de dure GPU-race verslaat en wat dit betekent voor jouw AI-investeringen
Het MIT-onderzoek dat aantoont waar de échte banenimpact van AI plaatsvindt (spoiler: niet bij de techneuten)
Hoe Anthropic het geheugenprobleem van AI-agenten oplost en waarom workflows belangrijker worden dan prompts
De komst van advertenties in ChatGPT en de nieuwe strijd om zichtbaarheid in AI-antwoorden
Het einde van ‘Brute Force’ AI? Waarom twee 22-jarigen Elon Musk buiten lieten staan

Je moet behoorlijk stevig in je schoenen staan om ‘nee’ te zeggen tegen een blanco cheque van Elon Musk. Toch is dat precies wat William Chen en Guan Wang deden. Deze twee 22-jarige studenten zagen iets wat de rijkste man ter wereld op dat moment miste: de strategie van simpelweg meer rekenkracht tegen een probleem aangooien, is failliet.
In plaats van zich te laten inlijven door xAI, bouwden ze vanuit een lab in Beijing hun eigen startup: Sapient Intelligence. En het resultaat zet de verhoudingen in Silicon Valley op scherp. Hun prototype model, met slechts een fractie van de omvang van GPT-5, verslaat de giganten van OpenAI, Anthropic en Google op complexe redeneertaken.
Jarenlang gold in AI de ‘Scaling Law’ als heilige graal: stop meer data en meer peperdure GPU’s in een model, en het wordt vanzelf slimmer. Maar die vlieger gaat niet langer op. Zwaargewichten zoals Ilya Sutskever (ex-OpenAI) en Yann LeCun (Meta) waarschuwen al maanden dat deze methode tegen een muur loopt. De data is op, de energierekening is onhoudbaar en de modellen worden nauwelijks meer slimmer, alleen maar duurder.
De jongens van Sapient bewijzen dit in de praktijk. In plaats van een groter brein te bouwen, bouwden ze een efficiënter brein. Hun ‘Hierarchical Reasoning Model’ (HRM) bootst de menselijke denkwijze na. Zie het als het verschil tussen je reflexen en je diepe concentratie. Waar een standaard taalmodel (LLM) vooral heel goed is in het voorspellen van het volgende woord (een reflex), splitst het model van Sapient taken op in ‘snel denken’ en ‘traag, logisch redeneren’. Hierdoor ‘gokt’ het model niet, maar plant het.
Wat betekent dit concreet voor de Nederlandse ondernemer?
De implicaties hiervan reiken verder dan technische benchmarks. We bewegen ons van een tijdperk van kracht naar een tijdperk van architectuur. Dit heeft directe gevolgen voor jouw strategie:
Kostenreductie en onafhankelijkheid: Je hebt straks geen serverpark van miljoenen meer nodig om ‘state-of-the-art’ intelligentie te draaien. Als een klein model op consumentenhardware kan redeneren als een groot model, wordt het ineens haalbaar om krachtige AI lokaal te draaien (’on-premise’). Dat scheelt niet alleen in de cloud-kosten, maar lost ook direct een groot deel van je privacy-hoofdpijn op.
Van babbelen naar werken: Huidige LLM’s zijn fantastische babbelaars, maar matige werknemers. Ze hallucineren omdat ze taal genereren, geen logica. De nieuwe generatie modellen, zoals die van Sapient Intelligence, is gebouwd om taken uit te voeren en problemen op te lossen. Dit maakt ze veel betrouwbaarder voor bedrijfskritische processen, zoals logistieke planning of financiële analyses.
Specialisatie wint van generalisatie: De focus verschuift van ‘één model dat alles kan’ naar kleinere, gespecialiseerde modellen die excelleren in specifieke taken. Voor jouw bedrijf betekent dit dat je niet hoeft te wachten op GPT-5, maar nu al winst kunt boeken door slimme, compacte modellen in te zetten op specifieke knelpunten.
Toch moeten we ook hier een kritische kanttekening plaatsen. Het is verleidelijk om mee te gaan in het enthousiasme over ‘het verslaan van de reuzen’. Maar benchmarks zijn nog geen business cases. Dat het model van Sapient briljant is in het oplossen van ‘Sudoku-Extreme’ of abstracte puzzels, betekent niet automatisch dat het morgen feilloos jouw klantenservice kan overnemen of juridische contracten kan redigeren. De vertaalslag van abstract redeneervermogen naar rommelige, menselijke bedrijfsprocessen blijft een beruchte horde, de zogeheten ‘implementation gap’. Bovendien is het nog maar de vraag of startups als Sapient hun voorsprong behouden zodra de grote techbedrijven hun miljardenbudgetten volledig op deze nieuwe architectuur richten.
De tijd van ‘groter is beter’ is voorbij. Voor zakelijk Nederland is het signaal helder: staar je niet blind op de volgende generatie megamodellen uit Silicon Valley. De echte winst ligt de komende jaren in slimme architectuur en gespecialiseerde systemen die minder rekenkracht vreten, maar beter kunnen redeneren. Wachten op ‘algemene intelligentie’ is zinloos; investeren in specifieke, efficiënte toepassingen die nu al werken, is de enige logische zet.
Het ‘IJsberg-effect’: Waarom de echte AI-impact onzichtbaar blijft
Als je de afgelopen maanden het nieuws hebt gevolgd, zou je bijna denken dat softwareontwikkelaars een uitstervend ras zijn. De verhalen over AI die ‘beter codeert dan mensen’ vliegen je om de oren. En eerlijk is eerlijk: het idee dat de bouwers van de technologie als eersten overbodig worden, heeft een zekere ironie.
Maar wie zich blindstaart op Silicon Valley, mist het grotere plaatje volledig.
Nieuw onderzoek van MIT zet die aanname namelijk op losse schroeven. Ze noemen het Project Iceberg, en die naam is niet toevallig gekozen. De onderzoekers hebben berekend welke banen technisch gezien nu al overgenomen kunnen worden door AI. Wat blijkt? De programmeurs en techneuten, de groep waar iedereen het over heeft, vormen slechts het topje van de ijsberg. Hun werk vertegenwoordigt ongeveer 2,2 procent van de totale loonsom in de VS.
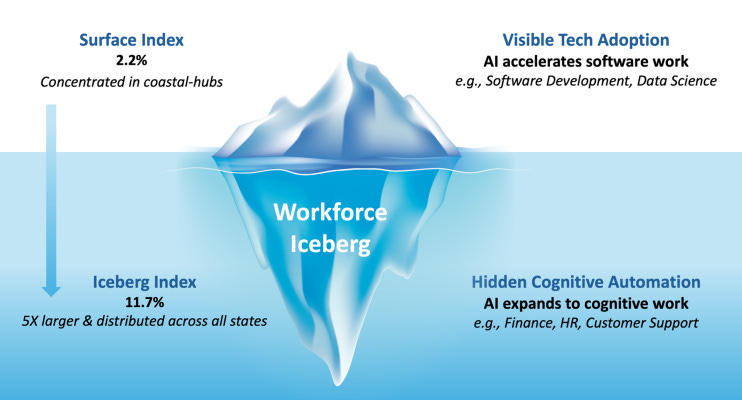
Het echte verhaal speelt zich ‘onder water’ af.
Daar vind je een enorme massa aan administratieve, financiële en ondersteunende functies. Denk aan de boekhouder die facturen controleert, de HR-medewerker die contracten opstelt, of de medewerker klantenservice die standaardvragen beantwoordt. Volgens de Iceberg Index is de blootstelling aan AI hier bijna vijf keer zo groot: 11,7 procent van de totale loonwaarde.
Voor de duidelijkheid: we hebben het hier over een economische waarde van 1,2 biljoen dollar die in de gevarenzone zit. Terwijl wij ons druk maken over de toekomst van programmeren, vindt de grootste verschuiving plaats in de back-office van het gemiddelde MKB-bedrijf.
Wat dit extra interessant maakt voor ondernemers, is dat het hier vaak gaat om processen die we al jaren als ‘noodzakelijk kwaad’ beschouwen. Waar creatief werk lastig te automatiseren blijft, blinkt de huidige generatie AI juist uit in het structureren van chaos: formulieren invullen, data overtypen en rapportages draaien.
Toch zit hier een addertje onder het gras dat vaak over het hoofd wordt gezien.
De onderzoekers van MIT maken een scherp onderscheid tussen wat AI technisch kan en wat bedrijven daadwerkelijk gaan doen. Dat een algoritme het werk van een junior analist kan doen, betekent niet dat die functie morgen verdwijnt. Veel organisaties zitten nog vast in verouderde systemen, of worstelen met privacyregels die in Europa (terecht) streng zijn. De theorie loopt hier mijlenver voor op de weerbarstige praktijk.
Bovendien roept dit een fundamenteel probleem op voor de lange termijn: de ‘kennis-kloof’. Als AI al het instapwerk overneemt, het zogenaamde ‘grunt work’ waar juniors het vak mee leren, hoe leiden we dan nog de experts van de toekomst op? Je kunt geen senior strateeg worden als je nooit met je voeten in de modder hebt gestaan.
In een analyse analyse van Bright merkt men terecht op dat overheden die enkel naar werkloosheidscijfers kijken, de boot gaan missen. De banen verdwijnen misschien niet direct, maar de inhoud ervan verandert onherkenbaar. Een financieel analist zal minder tijd kwijt zijn aan Excel-sheets vullen en meer aan het interpreteren van de uitkomsten. Tenminste, dat is het optimistische scenario.
In de praktijk betekent dit vooral dat de concurrentiestrijd verschuift van ‘wie heeft de beste mensen’ naar ‘wie haalt de wrijving uit zijn processen’. Bedrijven die nu nog vertrouwen op handmatig administratief werk, bouwen in rap tempo een technische en financiële achterstand op. De winst zit hem niet in het vervangen van mensen, maar in het weghalen van de administratieve rompslomp die hun eigenlijke werk in de weg zit.
Blauwdruk voor de digitale werknemer: Hoe Anthropic het geheugenprobleem oplost

Iedereen die wel eens heeft geprobeerd om ChatGPT of Claude een complexe applicatie te laten bouwen, kent het fenomeen: het begint veelbelovend. De code stroomt eruit, de ideeën zijn scherp. Maar naarmate de chatsessie langer duurt, begint de AI te hallucineren. Hij vergeet eerdere instructies, draait in cirkels en schrijft code die functies breekt die vijf minuten geleden nog werkten.
Het is alsof je samenwerkt met een briljante stagiair die elke tien minuten een klap op zijn hoofd krijgt en zijn geheugen verliest.
Dit ‘context-probleem’ is tot nu toe de grootste barrière geweest voor echt autonome AI-agenten. Maar Anthropic heeft een technische strategie gedeeld die dit kan veranderen. Ze introduceren geen nieuw model, maar een nieuwe architectuur voor hoe we met modellen werken.
De oplossing klinkt bedrieglijk simpel: stop met proberen alles in één keer te doen.
In plaats van één AI-agent die als een kip zonder kop probeert een heel project te bouwen, stelt Anthropic een strikte scheiding van taken voor. Ze splitsen het proces in tweeën:
De Initializer Agent: Zie dit als de architect of projectmanager. Deze AI schrijft geen code, maar zet de lijnen uit. Hij maakt een gedetailleerd masterplan (in het geval van Anthropic‘s test: een lijst van meer dan 200 specifieke features) en zet de ontwikkelomgeving klaar. Zijn werk stopt daar.
De Coding Agent: Dit is de uitvoerder. Deze agent pakt één taak van de lijst, bouwt het, test het, en—cruciaal—legt vast wat hij heeft gedaan in een extern bestand. Daarna wordt zijn geheugen gewist en begint hij ‘schoon’ aan de volgende taak, met alleen het masterplan en de voortgangsnotities als gids.
Wat dit extra interessant maakt, is dat het de manier waarop we naar AI kijken verandert. We gaan van een ‘chat-interface’ naar een ‘productielijn’. Door de AI te dwingen zijn voortgang extern op te slaan (bijvoorbeeld in een JSON-bestand of via Git commits), maak je hem onafhankelijk van zijn beperkte kortetermijngeheugen.
Voor Nederlandse ondernemers en technische teams betekent dit concreet dat de droom van ‘AI die werkt terwijl jij slaapt’ dichterbij komt. Waar je voorheen constant moest micromanagen om te voorkomen dat de AI ontspoorde, biedt deze modulaire aanpak een vangnet. Als de agent een fout maakt, kun je simpelweg terugrollen naar de vorige commit, zonder dat de hele context van het gesprek verloren gaat.
Toch is er een belangrijke kanttekening te plaatsen bij dit optimisme.
De zwakke plek in deze blauwdruk is de kwaliteitscontrole. Anthropic merkte in hun tests op dat de Coding Agent de neiging heeft om lui te worden met testen. De AI markeert een taak als ‘voltooid’ omdat de code er goed uitziet, zonder te verifiëren of de app daadwerkelijk werkt in de browser.
Als je dit proces volledig automatiseert zonder menselijke checks tussendoor, loop je het risico op een ‘schone’ codebase die functioneel nergens op slaat. Je bouwt dan heel efficiënt een kaartenhuis.
De conclusie voor de lange termijn is helder: het wachten is niet op een nog slimmer model, maar op betere workflows. Bedrijven die nu investeren in het structureren van hun AI-processen—het scheiden van denken (architectuur) en doen (code)—zullen de eersten zijn die autonome agenten succesvol in productie nemen. Succes zit hem niet in de ‘prompt’, maar in het proces.
Advertenties in ChatGPT
Geniet nog heel even van de rust in je chatvenster. Het was een kwestie van tijd, maar de dagen dat ChatGPT fungeerde als een neutrale, reclamevrije assistent zijn geteld. We wisten allemaal dat de enorme rekenkracht ergens van betaald moest worden, en nu ligt het bewijs op tafel.

In de code van de ChatGPT Android-app zijn door ontwikkelaars sporen gevonden die weinig aan de verbeelding overlaten. Termen als “bazaar content”, “search ad” en “search ads carousel” wijzen erop dat OpenAI zich klaarmaakt om de strijd aan te gaan met het verdienmodel van Google.
Dit is geen klein experimentje in de marge. Met inmiddels 800 miljoen wekelijkse gebruikers heeft OpenAI een kritische massa bereikt die voor adverteerders onweerstaanbaar is. Waar je bij Google nog door een lijst blauwe links scrolt, geeft AI je direct antwoord. En precies daar, in dat ene directe antwoord, ontstaat nu ruimte voor commerciële beïnvloeding.
Wat dit extra interessant maakt voor Nederlandse ondernemers, is de verschuiving van SEO (Search Engine Optimization) naar wat we AIO (Artificial Intelligence Optimization) kunnen noemen.
Stel je voor: iemand vraagt ChatGPT om ‘de beste boekhoudsoftware voor een ZZP’er’. Tot nu toe bepaalde het algoritme het antwoord op basis van beschikbare data. Straks kan dat antwoord beïnvloed worden door wie de hoogste prijs betaalt voor die positie. Dit verandert je marketingstrategie fundamenteel. Je vecht niet meer om een plekje op pagina één, maar om onderdeel te zijn van het antwoord.
De kracht van AI zat tot nu toe in de perceptie van objectiviteit. We zien de chatbot als een slimme adviseur, niet als een verkoper.
Zodra commercie de antwoorden gaat kleuren, ontstaat er een vertrouwensbreuk. Als ChatGPT straks een product aanbeveelt, is dat dan omdat het daadwerkelijk de beste keuze is, of omdat er betaald is voor ‘search ad placement’? Het risico bestaat dat de kwaliteit van de output ondergeschikt raakt aan de commerciële belangen, precies het probleem waar zoekmachines al jaren mee worstelen.
Voor marketingmanagers en ondernemers betekent dit concreet dat je nu moet inventariseren hoe jouw merk wordt weergegeven in AI-antwoorden. De strijd om zichtbaarheid verplaatst zich van de zoekbalk naar de prompt.
Zorg dat je budget vrijmaakt voor deze nieuwe advertentievorm en begin nu al met het testen van je merkbekendheid binnen taalmodellen. Wie nu al ‘AI-ready’ is, heeft straks de eerste keuze op de nieuwe digitale marktplaats.
The Shortlist
PEXI lanceert een publieke MCP-server waarmee marketeers advertentiecampagnes direct vanuit AI-chatbots zoals Claude kunnen aansturen en analyseren, een primeur voor het Groningse platform die de workflow van digitale marketingteams drastisch versnelt.
OpenAI bevestigt een datalek bij analysepartner Mixpanel waardoor contactgegevens van API-klanten zijn blootgesteld, en adviseert bedrijven alert te zijn op gerichte phishingpogingen hoewel kritieke inloggegevens veilig zijn gebleven.
USPTO publiceert nieuwe richtlijnen die vaststellen dat AI-systemen juridisch geen uitvinder kunnen zijn, waardoor patenten exclusief blijven voor menselijke innovatie, zelfs wanneer deze zwaar leunt op generatieve modellen als hulpmiddel.
Google brengt zijn AI-assistent Gemini naar Maps, waardoor bestuurders via spraakopdrachten complexe zoekvragen over hun omgeving en route kunnen stellen zonder het scherm aan te raken.